서비큐라님의 초보를 위한 도커 안내서
- 초보를 위한 도커 안내서 - 도커란 무엇인가? SERIES 1/3
- 초보를 위한 도커 안내서 - 설치하고 컨테이너 실행하기 SERIES 2/3
- 초보를 위한 도커 안내서 - 이미지 만들고 배포하기 SERIES 3/3
Docker 치트 시트
'Docker' 카테고리의 다른 글
| Docker Network 구조 (0) | 2018.04.22 |
|---|---|
| [번역]시작하는 이들을 위한 컨테이너, VM, 그리고 도커에 대한 이야기 (0) | 2018.04.22 |
| 도커 사용 후기 (0) | 2017.01.06 |
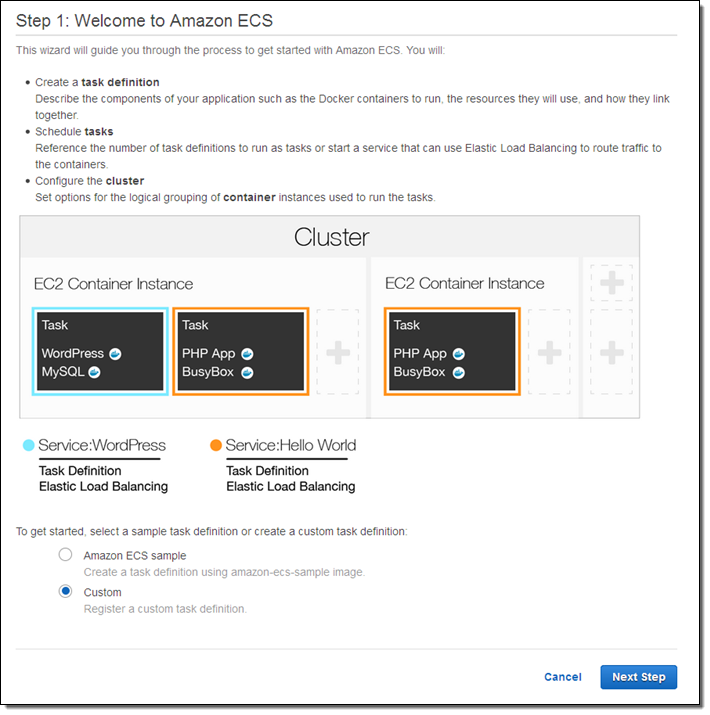
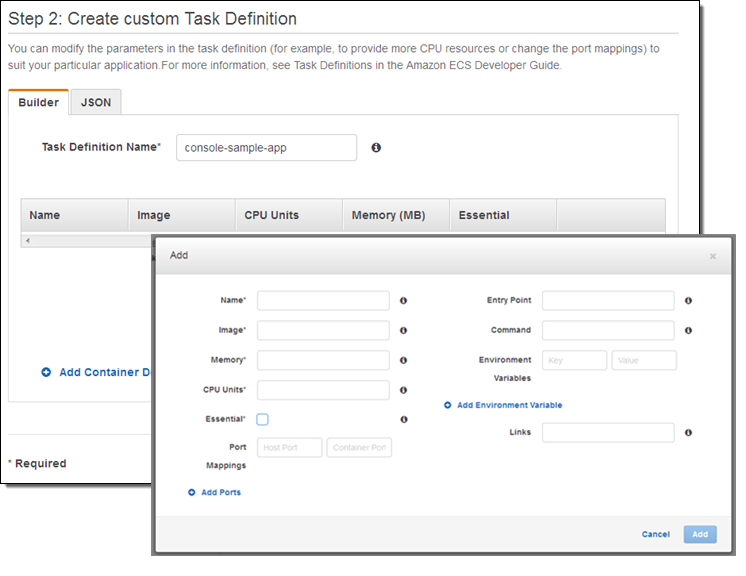
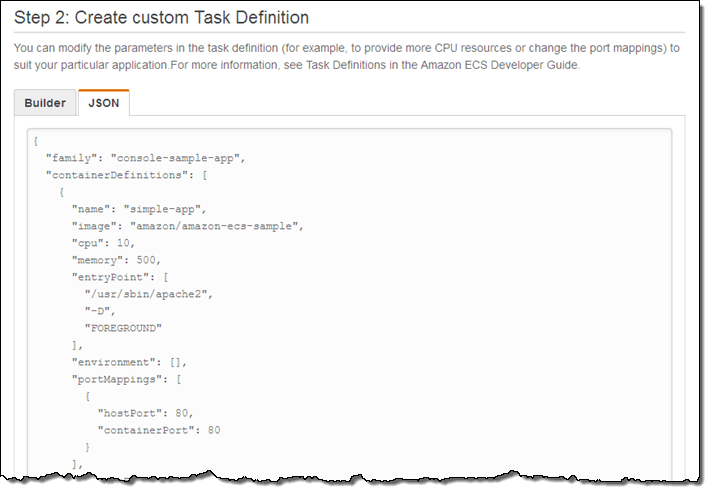
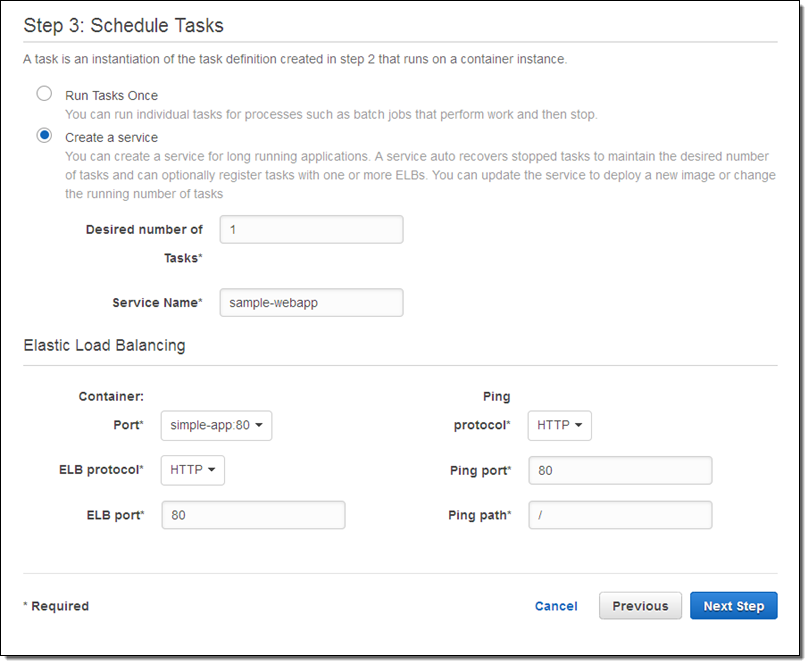
| Announcement: Amazon EC2 Container Service is Now Generally Available (0) | 2015.04.16 |
| EC2 Container Service – Long-Running Applications, Load Balancing, and More (0) | 2015.04.13 |